O Custo Oculto dos Arrays no PostgreSQL

- Published on
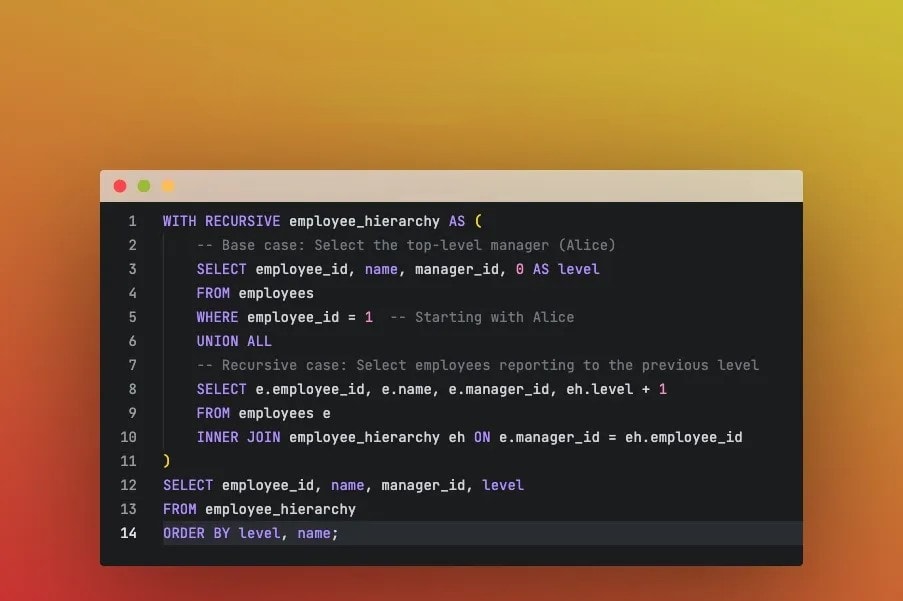
Começar a trabalhar com arrays no PostgreSQL é tão simples quanto declarar uma coluna como integer[], inserir alguns valores e pronto.
Ou criar o array dinamicamente.
SELECT '{1,2,3}'::int[];
SELECT array[1,2,3];
int4
--------
{1,2,3}
(1 row)
array
--------
{1,2,3}
(1 row)
A documentação oficial fornece uma boa introdução. Mas por trás dessa interface simples está um conjunto de propriedades mais complexas do que a maioria de nós imagina. Arrays no PostgreSQL não são apenas "listas" em um campo. Eles têm sua própria estratégia de gerenciamento de memória, sua própria lógica de indexação e muitos cenários de casos extremos.
A tentação do modelo de documento
Espere? Vamos falar sobre arrays JSONB? Nem um pouco. Todo o conceito de arrays em SGBDs relacionais é, na verdade, armazenamento de documento disfarçado.
No design de banco de dados, a localidade garante tempos de recuperação mais rápidos mantendo dados relacionados próximos no armazenamento físico. Seja usando um tipo integer[] distinto ou uma lista JSON [1, 2, 3], você está tomando exatamente a mesma decisão arquitetural: está priorizando a localidade em vez da normalização.
Quando você armazena tag_ids em um array, está incorporando dados relacionados diretamente em uma linha – exatamente como um banco de dados NoSQL poderia incorporar subdocumentos. Isso não é inerentemente errado. Bancos de dados de documento existem por bons motivos: eliminam joins, simplificam leituras e mapeiam naturalmente para objetos de aplicação.
Mas o PostgreSQL é um banco de dados relacional. Foi projetado em torno do modelo relacional, onde:
- chaves estrangeiras garantem integridade referencial
- joins conectam tabelas normalizadas
- atualizações modificam linhas individuais, não listas inteiras
Arrays oferecem a conveniência do modelo de documento, mas você perde as promessas relacionais. Não há chaves estrangeiras e nem ON DELETE (como CASCADE) para elementos de array. Se você excluir uma entrada da tabela tags, o ID órfão permanecerá em seu array para sempre.
A regra geral é: se você se encontrar precisando de integridade referencial – muito provavelmente quer uma tabela de ligação, não um array. Arrays são para dados que compartilham o mesmo ciclo de vida da linha pai. Não para relacionamentos que abrangem diferentes tabelas.
Um exemplo prático é o autor de um post de blog (um autor pode escrever vários outros posts), enquanto uma lista de permissões de endereços IP para uma conta de serviço é aplicável apenas à entidade em questão.
Com o JSONB sendo tão flexível, você pode se perguntar por que ainda nos preocupamos com tipos nativos mais peculiares. A resposta está na parte "chata" do banco de dados: previsibilidade e eficiência. Uma coluna integer[] garante que cada elemento seja um inteiro.
Arrays também são mais eficientes em armazenamento para primitivos porque não carregam a sobrecarga de metadados dos objetos JSON.
As armadilhas de sintaxe
Este post assume conhecimento básico de arrays. Não cobriremos o básico.
Arrays não precisam começar em 1
Por padrão, os arrays SQL começam no índice 1. E aparentemente, não há nada de errado em iterar por eles de uma forma semelhante a:
FOR i IN 1 .. array_length(fruits, 1) LOOP
RAISE NOTICE 'Index % contains: %', i, fruits[i];
END LOOP;
... até você encontrar um array com limites arbitrários. O que o PostgreSQL permite.
SELECT '[-5:-3]={10,20,30}'::int[];
Para garantir que você itere corretamente por qualquer array fornecido, sempre use array_lower() e array_upper() no PL/pgSQL.
SELECT array_lower('[-5:-3]={10,20,30}'::int[], 1);
array_lower
-------------
-5
(1 row)
... ou generate_subscripts() no SQL.
SELECT generate_subscripts('[-5:-3]={10,20,30}'::int[], 1);
generate_subscripts
---------------------
-5
-4
-3
(3 rows)
Dimensões ausentes
Ao criar uma tabela, você pode esperar uma tipagem estrita. Isso é verdade para tudo – exceto as dimensões do array. Você pode pensar que integer[][] impõe uma matriz 2D. Exceto que não. A sintaxe [] é efetivamente um açúcar sintático. O PostgreSQL não impõe o número de dimensões dos sub-arrays no nível do esquema por padrão.
CREATE TABLE dimension_test (
matrix integer[][]
);
INSERT INTO dimension_test VALUES ('{{1,2}, {3,4}}');
-- isso não vai falhar
INSERT INTO dimension_test VALUES ('{1,2,3}');
-- matriz 3D também funciona
INSERT INTO dimension_test VALUES ('{{{1,2},{3,4}}, {{5,6},{7,8}}}');
Se você quiser impor uma dimensão de array específica, não pode confiar na definição de tipo. Em vez disso, deve usar uma restrição CHECK.
CREATE TABLE strict_matrix (
-- dims: garantir que é 2-Dimensional
-- array_length: garantir que é exatamente 3x3
board integer[] CHECK (array_ndims(board) = 2 AND array_length(board, 1) = 3)
);
INSERT INTO strict_matrix VALUES (
ARRAY[
[0, 1, 0],
[1, 1, 0],
[0, 0, 1]
]
);
A única exceção é que o PostgreSQL impõe uniformidade dos arrays em cada nível de aninhamento. Isso significa que rejeita sub-arrays com tamanhos diferentes.
INSERT INTO dimension_test VALUES ('{{1,2}, {3}}');
ERROR: malformed array literal: "{{1,2}, {3}}"
LINE 1: INSERT INTO dimension_test VALUES ('{{1,2}, {3}}');
^
DETAIL: Multidimensional arrays must have sub-arrays with matching dimensions.
Fatiando (Slicing) arrays
Ao acessar valores de array, é importante considerar que a sintaxe [1] e [1:1] são diferentes. Enquanto o primeiro é um acessador, o segundo age como um construtor.
select matrix[1][1] from dimension_test ;
matrix
--------
1
(1 row)
Ao usar slice um array, mesmo que o slice seja de um único elemento, ela será retornada como um array de um único elemento, não como um valor escalar.
select matrix[1:1][1:1], matrix[1][1:1], matrix[1:1][1] from dimension_test ;
matrix | matrix | matrix
--------+--------+--------
{{1}} | {{1}} | {{1}}
(1 row)
A parte feia
Acessar valores de array tem um comportamento tolerante, tornando mais difícil encontrar bugs subjacentes:
-- acesso fora dos limites retorna NULL
SELECT (ARRAY[1,2,3])[10];
array
-------
(null)
(1 row)
-- fatiamento fora dos limites retorna um array vazio
SELECT (ARRAY[1,2,3])[5:10];
array
-------
{}
(1 row)
Mas o aspecto mais confuso que pode pegá-lo, vindo de outras linguagens de programação, é o fato de que o PostgreSQL trata arrays multidimensionais como uma única matriz, não como um array de arrays.
-- dimensionalidade errada
SELECT (ARRAY[[1,2],[3,4]])[1];
array
-------
(null)
(1 row)
Enquanto em outras linguagens você espera {1,2} como resultado, o PostgreSQL não pode te dar isso. Ele tenta retornar a primeira célula e falha (porque o índice não está completo).
E parafraseando a analogia do "Double Bubble" de Fletcher (que também deu muito errado – pontos extras para quem pegou a referência), você não pode consertar isso usando a notação slice.
select ('{{1,2},{3,4}}'::int[])[1:1];
int4
---------
{{1,2}}
(1 row)
A única maneira de resolver esse quebra-cabeça é desaninhar (unnest) o slice e re-agregar os resultados.
SELECT array_agg(val) FROM unnest(('{{1,2},{3,4}}'::int[])[1:1]) val;
array_agg
-----------
{1,2}
(1 row)
Apenas esteja ciente de que o array_agg não garante a ordem dos elementos agregados, a menos que você use uma cláusula ORDER BY. Embora geralmente funcione com consultas simples de unnest, confiar na ordenação implícita pode ser arriscado.
A outra alternativa é convertê-lo para JSONB e vice-versa. Não fica bonito, não importa como você olhe. Se você precisa trabalhar com estruturas multidimensionais complexas onde cada sub-array tem significado independente, apenas use JSONB. Ele fará exatamente o que você espera.
Indexando arrays
Embora você possa usar um índice B-tree em uma coluna de array, isso não ajudará a menos que você esteja procurando por igualdade de array inteiro e ordenando um array por regras de dicionário.
-- qual é maior? B está correto
-- A: {1, 1000, 1000}
-- B: {2, 0}
Isso torna os índices B-tree inúteis para qualquer operação de indexação do mundo real.
Ao trabalhar com arrays, você realmente precisa do GIN (Generalized Inverted Index). Se um índice B-tree é uma lista telefônica, o GIN é um índice no final do livro. Para consultar um ou mais elementos, você precisa encontrar todas as localizações possíveis e então intersectá-las para encontrar as localizações que correspondem.
CREATE INDEX posts_by_tags ON posts USING GIN (tags);
Os índices GIN são projetados para operações de conjunto, tornando a presença a característica principal, enquanto ignoram a ordem. Aqui estão os operadores que o GIN fornece para arrays:
Contenção @> – corresponde às linhas que incluem TODOS os itens selecionados.
-- corresponde a TODAS as tags
tags @> '{urgent, bug}'
Sobreposição && – a linha inclui QUALQUER um dos itens selecionados?
-- corresponde a bug ou feature
tags && '{bug, feature}'
Há também <@ e = (igualdade), mas eles devem ser fáceis de entender.
Os dois lados do ANY
É aqui que fica interessante. Embora você possa frequentemente ouvir (eu incluso) que não deve usar SQL dinâmico para listas IN e deve usar ANY em vez disso, existem alguns perigos que você precisa conhecer.
O operador ANY se comporta de maneira muito diferente dependendo de qual lado da comparação o array está.
O conselho para usar ANY é válido quando você está passando listas para o banco de dados. Em vez de gerar uma consulta com 100 parâmetros distintos (WHERE id IN ($1, $2, ... $100)), que incha seu cache de consulta e força hard-parses, você deve passar um único parâmetro de array.
-- bom: um parâmetro, um plano de consulta
SELECT * FROM users WHERE id = ANY($1::int[]);
A armadilha é assumir que essa sintaxe é igualmente eficiente ao consultar colunas de array. Não é. Se você usar ANY para verificar se um valor existe dentro de uma coluna da tabela, está efetivamente pedindo ao banco de dados para fazer um loop.
-- ruim: GIN não suporta ANY; transforma isso em uma varredura sequencial
SELECT * FROM tickets WHERE 'feature' = ANY(tags);
Quando você escreve WHERE 'feature' = ANY(tags), você não está usando um operador de array. O que você escreveu é um operador de igualdade escalar = aplicado dentro de uma construção de loop. Como o operador escalar = não faz parte do array_ops, o planejador assume que o índice não pode ajudar e recai para uma varredura sequencial.
A maneira correta de reescrever a consulta é:
-- bom novamente
SELECT * FROM tickets WHERE tags @> ARRAY['feature'];
Atualizações rápidas e a troca
Porque um índice GIN é construído para trabalhar com conjuntos, ele é caro para manter. Com um índice B-tree, uma linha é igual a uma entrada de índice. Em um índice GIN, uma linha é igual a N entradas de índice, onde N é o número de elementos no seu array.
Isso leva à multiplicação de escrita. Para evitar isso, o PostgreSQL usa por padrão um mecanismo de "atualização rápida". Esta é uma estratégia onde novas entradas são adicionadas a uma lista pendente (um buffer temporário não ordenado) e só são mescladas na estrutura principal do índice posteriormente (durante o VACUUM).
Dada a natureza não ordenada de um índice GIN, ele é uma exceção ao "VACUUM is a Lie" (O VACUUM é uma mentira), pois o VACUUM realmente faz manutenção estrutural aqui. Enquanto isso torna as operações INSERT gerenciáveis, pode desacelerar os SELECTs. Cada vez que você consulta o índice, o PostgreSQL deve verificar o índice principal organizado mais a bagunçada lista pendente inteira. Se essa lista crescer muito, o desempenho da sua consulta pode se degradar.
Se você opera um fluxo de trabalho pesado em leitura com escritas infrequentes, deve desativar isso para garantir um desempenho de leitura consistente.
CREATE INDEX posts_by_tags ON posts USING GIN (tags) WITH (fastupdate = off);
Armazenamento e modificação
Agora é hora de voltar ao modelo de documento. No PostgreSQL, as linhas são imutáveis (MVCC); não existe algo como uma "atualização in-place", e os arrays são armazenados como valores atômicos. Isso resulta em uma verdade muito desconfortável – para modificar um único elemento de um array, o PostgreSQL deve copiar e reescrever a linha inteira.
UPDATE user_activity
SET event_ids = event_ids || 10001
WHERE user_id = 50;
Cada acréscimo reescreve o array inteiro, o que, na prática, resulta na reescrita de toda a linha.
TOASTed
Quando qualquer array cresce o suficiente (> 2 KB – veja abaixo), o PostgreSQL o move automaticamente para uma área de armazenamento separada usando TOAST. Embora isso mantenha a linha de dados enxuta, transforma as atualizações de array em um sério gargalo de desempenho.
A diferença que isso introduz é sutil, mas tem um grande impacto. Enquanto uma atualização padrão do MVCC simplesmente copia a versão da linha no heap principal, atualizar um array TOASTed força o PostgreSQL a buscar todos os fragmentos externos, descomprimir o objeto inteiro na memória, aplicar a alteração e, em seguida, recomprimir e escrever o blob de tamanho completo de volta para a tabela TOAST. Isso transforma uma modificação simples em uma operação intensiva de CPU e I/O que reescreve o conjunto de dados inteiro, em vez de apenas o delta.
O limite é derivado de TOAST_TUPLES_PER_PAGE (padrão: 4), garantindo que 4 tuplas caibam em uma página.
Limite: ~2 KB
De onde vem o valor 2 KB? O limite TOAST é calculado para garantir que pelo menos quatro tuplas possam caber em uma única página de heap de 8 KB. O PostgreSQL usa isso para equilibrar eficiência contra a sobrecarga da indireção TOAST.
As compressões
Antes da versão 14, o PostgreSQL dependia do pglz – um algoritmo que priorizava a taxa de compressão em vez da velocidade. Isso tornava o ciclo "descomprimir-modificar-comprimir" do TOAST doloroso.
O PostgreSQL 14 introduziu o LZ4 como uma alternativa:
ALTER TABLE articles ALTER COLUMN tags SET COMPRESSION lz4;
O LZ4 é significativamente mais rápido para compressão e descompressão, com apenas taxas de compressão ligeiramente menores. Se você está trabalhando com arrays grandes, mudar para o LZ4 é uma das maneiras mais fáceis de reduzir a penalidade de CPU do TOAST.
Quando um array grande pode fazer sentido
Você pode ter tido a impressão de que arrays são ruins. Ao avaliar o uso de arrays, a verdadeira questão não é quão grande é o array, mas sim com que frequência você o modifica? Um array de 10.000 elementos que você escreve uma vez e é somente leitura pelo resto de seu ciclo de vida é um caso de uso completamente válido. Um array de 50 elementos ao qual você anexa a cada solicitação recebida é o verdadeiro vilão aqui.
Se você combinar isso com compressão, pode obter uma mistura interessante.
DROP TABLE IF EXISTS compression_test;
CREATE TABLE compression_test (
id serial PRIMARY KEY,
compressed_floats float4[],
raw_floats float4[]
);
-- do not compress raw_floats
ALTER TABLE compression_test ALTER COLUMN raw_floats SET STORAGE EXTERNAL;
-- insert semi-random data with low cardinality
INSERT INTO compression_test (compressed_floats, raw_floats)
SELECT semi_random_arr, semi_random_arr
FROM (
SELECT ARRAY(
SELECT floor(random() * 50)::float4
FROM generate_series(1, 10000)
) as semi_random_arr
) as generator;
SELECT
'Compressed (EXTENDED)' as strategy,
pg_size_pretty(pg_column_size(compressed_floats)::bigint) as size_on_disk
FROM compression_test
UNION ALL
SELECT
'Raw (EXTERNAL)',
pg_size_pretty(pg_column_size(raw_floats)::bigint)
FROM compression_test;
strategy | size_on_disk
-----------------------+--------------
Compressed (EXTENDED) | 15 kB
Raw (EXTERNAL) | 39 kB
(2 rows)
Carregamento em massa com arrays
Até agora, pode parecer que os arrays não trazem muitos benefícios reais. Embora possam apresentar dificuldades relacionadas ao armazenamento, eles são incrivelmente úteis para transporte.
A maneira mais rápida de inserir 5.000 linhas não é um loop na sua aplicação, e definitivamente não é uma string massiva com VALUES (...), (...). É o unnest.
INSERT INTO measurements (sensor_id, value, captured_at)
SELECT * FROM unnest(
$1::int[], -- array de IDs de sensores
$2::float[], -- array de valores
$3::timestamptz[] -- array de timestamps
);
Tudo o que é necessário é uma única ida e volta na rede e uma consulta para análise e planejamento. O PostgreSQL processa os arrays linha por linha internamente para você. Isso funciona tanto para UPSERTs quanto para MERGE.
Os casos para arrays especiais
Os arrays padrão do PostgreSQL são tipos polimórficos (anyarray). Isso fornece um recurso poderoso que permite que uma única definição de função opere em muitos tipos de dados diferentes. Eles precisam lidar igualmente bem com inteiros, strings, timestamps e tipos personalizados. Mas se você tem tipos de dados específicos, pode desbloquear ganhos significativos de desempenho usando extensões especializadas.
A extensão intarray
Se você está lidando exclusivamente com inteiros de 4 bytes (int4/integer), as operações de array integradas estão deixando desempenho na mesa. A extensão intarray fornece funções e operadores de índice especializados que são significativamente mais rápidos que a implementação genérica.
Para usá-la, você deve habilitá-la explicitamente:
CREATE EXTENSION IF NOT EXISTS intarray;
A diferença na ergonomia para o desenvolvedor é imediata. Para ordenar um array no SQL padrão, você é forçado a usar unnest, ordenar e reagregar. Com intarray, você obtém funções nativas como sort() e uniq().
-- arrays padrão
SELECT array_agg(val ORDER BY val)
FROM unnest('{3, 1, 2}'::int[]) val;
-- intarray
SELECT sort('{3, 1, 2}'::int[]);
Tudo o que é necessário é uma única ida e volta na rede e uma consulta para análise e planejamento. O PostgreSQL processa os arrays linha por linha internamente para você. Isso funciona tanto para UPSERTs quanto para MERGE.
Os casos para arrays especiais
Os arrays padrão do PostgreSQL são tipos polimórficos (anyarray). Isso fornece um recurso poderoso que permite que uma única definição de função opere em muitos tipos de dados diferentes. Eles precisam lidar igualmente bem com inteiros, strings, timestamps e tipos personalizados. Mas se você tem tipos de dados específicos, pode desbloquear ganhos significativos de desempenho usando extensões especializadas.
A extensão intarray
Se você está lidando exclusivamente com inteiros de 4 bytes (int4/integer), as operações de array integradas estão deixando desempenho na mesa. A extensão intarray fornece funções e operadores de índice especializados que são significativamente mais rápidos que a implementação genérica.
Para usá-la, você deve habilitá-la explicitamente:
CREATE EXTENSION IF NOT EXISTS intarray;
A diferença na ergonomia para o desenvolvedor é imediata. Para ordenar um array no SQL padrão, você é forçado a usar unnest, ordenar e reagregar. Com intarray, você obtém funções nativas como sort() e uniq().
-- arrays padrão
SELECT array_agg(val ORDER BY val)
FROM unnest('{3, 1, 2}'::int[]) val;
-- intarray
SELECT sort('{3, 1, 2}'::int[]);
Além das funções básicas de gerenciamento, ela introduz uma sintaxe de consulta especializada que simplifica a lógica booleana complexa. Em vez de encadear múltiplas verificações de sobreposição (&&) e contenção (@>), você pode expressar seus requisitos em uma única "string de consulta" usando o operador @@.
-- arrays padrão
SELECT * FROM staff
WHERE available_days @> '{1}' -- deve incluir Seg
AND available_days && '{6, 7}' -- deve incluir Sáb OU Dom
AND NOT (available_days @> '{2}'); -- deve NÃO incluir Ter
-- intarray
SELECT * FROM staff
WHERE available_days @@ '1 & (6 | 7) & !2';
A única ressalva é a restrição de tipo. O intarray é estritamente limitado a inteiros com sinal de 32 bits. Se seus valores excederem 2 bilhões, você está de volta ao ponto de partida.
IA com pgvector
Você não pode falar sobre arrays em 2026 sem mencionar o pgvector. Embora se apresente como um "armazenamento de vetores", internamente é simplesmente um array de floats com um foco matemático diferente.
Arrays padrão são binários: eles se preocupam com Correspondências Exatas (Sobreposição &&, Contenção @>). Vetores são sobre distância aproximada (Cosseno <=>, Euclidiana <->).
Se você está construindo recursos de busca ou recomendação, o pgvector permite que você trate sua coluna de array não como uma lista de "fatos" (tag A, tag B), mas como coordenadas em um espaço semântico.
No entanto, a decisão arquitetônica é exatamente a mesma que usar um array padrão: você está trocando estrutura rígida por conveniência. Como não há como "unir" duas linhas com base em quão similares elas são, você armazena o vetor diretamente na linha. Você aceita um tamanho maior de tabela em troca da capacidade de perguntar: "O que está próximo a isto?".
Fique ligado
Seja um Expert em Growth
Receba insights práticos sobre marketing, dados, performance e tecnologia direto no seu email.